State of the Art in Code Generation
Table of Contents
Future tools will attack the more general problem of automatic code generation. Automatic programming is a difficult problem and it is still largely considered a research topic. Still, each new tool makes small innovations in this area, and eventually, code generation will become commonplace. — Alan S. Fisher (Fisher and Fisher 1988) (p. 30)
The trade-offs made by MASD can only be understood once the frame of reference of its parent approach, MDE, has been established and positioned against other techniques for the automatic development of software systems. The present document addresses this need by performing a state of the art review, centred on material of particular relevance to the methodology we shall put forward.
The document's structure mirrors our own trajectory across the MDE landscape. Section The Importance of Code Generation starts by making a broad case for code generation within the modern software engineering environment. Section Historical Approaches to Code Generation outlines a brief description of earlier approaches, with the aim of establishing an historical context. The remainder of the chapter is dedicated to a detailed exposition of what we consider to be the modern approach to code generation: MDE (Section Model Driven Engineering).
Our first step in this journey is then to establish the relevance of code generation to the present engineering moment by looking at the rise of code itself.
The Importance of Code Generation
Software systems experienced immense growth in size over the past fifty years. In 1970, Lion's commented version of the UNIX Operative System had around 10 thousand Lines of Code (LOC) (Lions 1996) and would fit comfortably in a book of less than 300 pages.1 By 2011, Feitelson and Frachtenberg reported that Facebook's 7-year-old codebase had 8 million LOC (Feitelson, Frachtenberg, and Beck 2013). Five years later, Potvin and Levenberg would nonchalantly tell us that "[Google's source code] repository contains 86TBa of data, including approximately two billion lines of code in nine million unique source files." (Potvin and Levenberg 2016) As it is with size, so it is with scope; these vast software systems are now so completely pervasive that Andreessen was led to conclude that "software is eating the world." (Andreessen 2011)
Software development processes evolved in tandem with the new reality. Modern software engineering involves multidisciplinary teams with fluid roles, and rigid views on product development have been replaced with flexible approaches emphasising problem solving — hallmarks of agile thinking (Beck et al. 2001). Integration, testing and deployment activities, once considered distinct from the development activity itself, have now all but been fused into a contiguous delivery stage by the DevOps movement and enshrined in Continuous Integration / Continuous Delivery (CI/CD) pipelines (Bou Ghantous and Gill 2017) (Sánchez-Gordón and Colomo-Palacios 2018). Some, such as Ameller et al., envision (emphasis ours):
[…] continuous software engineering going one step further by establishing strong connections between software engineering activities. The objective of these connections is to accelerate and increase the efficiency of the software engineering process. (Ameller et al. 2017)
The jury may still be out on Ameller's all-encompassing vision, but what is already beyond doubt is the drive to remove the human element from any and all activity amenable to automation. Here one finds a less obvious corollary to Andreessen's insightful observation: software is also eating software engineering too, for automation in this context is often synonymous with substituting resources — human or otherwise — with more code.2 The DevOps movement pushed forward a series of "X-as-code" initiatives, arguably the most noticeable of which is Infrastructure-as-Code (IaC) — the management of hardware infrastructure by programmatic means (Morris 2016) — along with others, perhaps less visible but of import still, such as Policy-as-Code (PoC) — which aims to "support separation of concerns, allow security decisions to be separated from infrastructure and application logic, and make it possible to unify security controls." (Herardian, Marshall, and Prendergast, n.d.) What DevOps has shown, in our opinion, is that anything that can, will become code because automation's value-add acts as a powerful forcing function.3
Automation may not be the only factor at play here, either. Where possible, software engineers prefer using code in the software development process over other kinds of artefacts, in no small part because its properties are now thought to be well understood.4 Large tooling ecosystems have been built to manage all aspects of its lifecycle, including diffing tools, Distributed Version Control Systems (DVCS), text editors, IDEs (Integrated Development Environments) and the like. Conversely, tools that do not support this paradigm seem to fall out of favour in the developer community. Badreddin et al. tell us about graphical modeling, where (emphasis ours) "[…] there is evidence that the adoption of visual modeling in software engineering remains low. The open source community remains almost entirely code centric."5 (Badreddin, Forward, and Lethbridge 2012)
If X-as-code — for all possible values of X — is the direction of travel, then its limit will surely be the tautological code-as-code; that is, the creation of code by automated means, or code generation. Given the rationale presented thus far for automation, one would naively expect code generation's role to increase hand-in-hand with the general growth of codebases, for, in a definite sense, it is the final frontier in the struggle for automation. It is the objective of the present work to shed light on the role of code generation on the modern software development process; to understand the limitations in its use; and, ultimately, to put forward an approach that addresses some of the identified weaknesses. As we shall see next, code generation has historically been an important component of the software engineer's toolkit.
Historical Approaches to Code Generation
The generation of source code by programmatic means, in the sense of automatic programming or programme synthesis6, has had a long history within Computer Science. Whilst many avenues have been explored and are worthy of examination, in the interest of space we narrowed our scrutiny down to two approaches: Computer-Aided Software Engineering (CASE) and Generative Programming (CP). These were chosen both because of their influence on the present work, on MDE itself and on related methodologies — e.g., (Jörges 2013). Let us start our brief excursion by considering the first of the pair.
Computer Aided Software Engineering (CASE)
The literature on CASE is expansive, and yet, in our opinion, it still fails to deliver an authoritative definition of the term. This is perhaps no more clearly illustrated than via Fisher's compendium (Fisher and Fisher 1988), where he first calls it a "nebulous term" and then dispenses not just one but two definitions, both of which rather broad in scope (emphasis ours):
One definition of computer-aided software engineering is the use of tools that provide leverage at any point in the software development cycle. […] A more restrictive but operationally better definition for computer-aided software engineering is the use of tools that provide leverage in the software requirements analysis and design specification phases, as well as those tools which generate code automatically from the software design specification. (Fisher and Fisher 1988) (p. 6)
Whatever its precise meaning, what most definitions have in common is the sketching of a wide domain boundary for CASE systems — supporting the full range of activities in the software engineering lifecycle — as well as providing automated "methods of designing, documenting and development of the structured computer code in the desired programming language." (Berdonosov and Redkolis 2011) CASE was, by any measure, an extremely ambitious programme, with lofty if laudable goals — as Fisher goes on to explain (emphasis ours):
The ultimate goal of CASE technology is to separate design from implementation. Generally, the more detached the design process is from the actual code generation, the better. (Fisher and Fisher 1988) (p. 5)
Though many of its ideas live on, perhaps unsurprisingly, the CASE programme as a whole did not take hold within the broad software engineering community — or, at least, not in the way most of those involved envisioned.7 Understanding why it was so imparts instructive lessons, particularly if you have an interest in automatic programming as does the present work. With similar thoughts in mind, Jörges (Jörges 2013) (p. 19) combed through the literature and uncovered a number of reasons which we shall now revisit, as well as supplementing them with two of our own towards the end.
- Deficiencies of translation into source code. Though instituting an incredibly diverse ecosystem8, most CASE tooling emphasised black-box transformation of graphical modeling languages into source code. There was a belief that automatic code generation for entire systems was looming in the horizon — with Fisher going as far as prophesying the emergence of "a software development environment so powerful and robust that we simply input the application's requirements specification, push a magic button, and out comes the implemented code, ready for release to the end user community." (Fisher and Fisher 1988) (p. 283) Perhaps due to this line of reasoning, generated code was often not designed to be modified, nor were systems built to support user defined code generators — both of which were required in practice. The resulting solutions were convoluted and difficult to maintain.
- Vendor lock-in. CASE predates the era of widely available Free and Open Source Software (FOSS), and therefore there was a predominance of proprietary software. As with vendor lock-in in general, it was not in the vendor's best interest to facilitate interoperability since, by doing so, it would inadvertently help customers migrate to a competitor's product. As a result, reusability and interoperability were severely hampered. In addition, given the proliferation of small and mid-sized vendors, there was a real difficulty in choosing the appropriate tool for the job — the consequences of which could only be judged long after purchase.
- Lack of support for collaborative development. Given the state of technology in the era when these tools were designed, it is understandable they did not adequately support the complex collaborative use cases that are required to facilitate the software engineering process. However, some of the difficulties transcended technology and were exacerbated by the vendor lock-in mentioned above; having data silos within each application — with narrow interfaces for data injection and extraction — meant it was difficult to supplement application workflows with external tooling.
- Limitations in graphical modeling languages. The generic nature of contemporary graphical modeling languages meant they were found wanting on a large number of use cases; oftentimes they were "too generic and too static to be applicable in a wide variety of domains" (Jörges 2013) (p. 20).
- Unfocused and overambitious vision. As already hinted by the lack of a formal definition, in our opinion CASE is a great example of a movement within software engineering that proposes an overly ambitious agenda, and one in which outcomes are extremely difficult to measure, either quantitatively or qualitatively. Due to this, it is hard to determine success and failure, and harder still to discern how its different components are fairing. In such a scenario, there is the risk of stating that "CASE failed" when, in reality, some of its key components may have been salvaged, modified and repackaged into other approaches such as MDE.
- Emphasis on full code generation. Subjacent to CASE's goals is the notion that one of the main impediments to full code generation of software systems is a formal language of requirements which is fit for purpose.9 However, in hindsight, it is now clear that attaining such a general purpose formal specification language is an incredibly ambitious target.
More certainly can be said on the subject of CASE's shortcomings, but, in our opinion, those six findings capture the brunt of the criticism. These lessons are important because, as we shall see (cf. Section Model Driven Engineering), MDE builds upon much of what was learned from CASE — even if it does not overcome all of its stated problems. However, before we can turn in that direction, we must first complete our historical review by summarising an approach with similar ambitions in the field of automatic programming.
Generative Programming
In sharp contrast with CASE's lighter approach to theory, Czarnecki's influential doctoral dissertation (Czarnecki 1998) extended his prior academic work — standing thus on firmer theoretical grounds. In it, he puts forward the concept of Generative Programming (GP). GP focuses on (emphasis ours):
[…] designing and implementing software modules which can be combined to generate specialized and highly optimized systems fulfilling specific requirements. The goals are to (a) decrease the conceptual gap between program code and domain concepts (known as achieving high intentionality), (b) achieve high reusability and adaptability, (c) simplify managing many variants of a component, and (d) increase efficiency (both in space and execution time). (Czarnecki 1998) (p. 7)
Of particular significance is the emphasis placed by GP on software families rather than on individual software products, as Czarnecki et al. elsewhere explain (emphasis ours):
Generative Programming […] is about modeling families of software systems by software entities such that, given a particular requirements specification, a highly customized and optimized instance of that family can be automatically manufactured on demand from elementary, reusable implementation components by means of configuration knowledge […]. (Czarnecki et al. 2000)
In sharp contrast with CASE (cf. Section CASE), GP provides a well-defined conceptual model, populated by a small number of core concepts which we shall now enumerate. At the centre lies the generative domain model, responsible for characterising the problem space (i.e., the domain of the problem), the solution space (i.e. the set of implementation components) as well as providing the mapping between entities in these spaces by means of configuration knowledge.10 Though GP does not dictate specific technological choices at any of the levels of its stack, Feature Models (Czarnecki, Helsen, and Eisenecker 2005) are often used as a means to capture relevant features of the problem domain, as well as relationships amongst them. Concrete software systems are obtained by specifying valid configurations, as dictated by the modeled features, and by feeding the configuration knowledge to a generator, which maps the requested configuration to the corresponding implementation components.
As with CASE, GP did not come to dominate industrial software engineering11, but many of the ideas it championed have lived on and are now central to MDE; the remainder of this chapter will cover some of these topics, with others described elsewhere (Craveiro 2021b) (Chapters 4 and 6 in particular). In our opinion, GP also benefited from cross-pollination with CASE — for example, by attempting to address some of its most obvious shortcomings such as de-emphasising specific technological choices and vendor products, and focusing instead on identifying the general elements of the approach. Alas, one downside of generalisation is the difficulty it introduces in evaluating the approach in isolation; many of the factors that determine the success or failure of its application are tightly woven with the circumstances and choices made by actors within a given instance of the software engineering process — a ghost that will return to haunt MDE (cf. FIXME Chapter). And it is to MDE which we shall turn to next.
Model Driven Engineering (MDE)
MDE is the final and most consequential stop on our quest to characterise the state of the art in automatic programming. The present section briefly reviews the core theoretical foundations of the discipline (Section What is Model-Driven Engineering), and subsequently delves into the specifics of two MDE variants of particular significance to MASD: MDA (Section Model Driven Architecture) and AC-MDSD (Architecture-Centric MDSD). Let us begin, then, by attempting to answer the most pressing question of all.
What is Model-Driven Engineering
Though the academic press has no shortage of literature on MDE12, it is largely consensual when it comes to its broad characterisation. Cuestas, for example, states the following (emphasis ours):
[Within MDE, software] development processes are conceived as a series of steps in which specification models, as well as those which describe the problem domain, are continually refined, until implementation domain models are reached — along with those which make up the verification and validation of each model, and the correspondence between them. In [MDE], the steps in the development process are considered to be mere transformations between models.13 (Cuesta 2016) (p. 1)
However, as we argued previously at length (Craveiro 2021b), this apparent consensus is somewhat misleading, and a characterisation of the fundamental nature of MDE is not as easy as it might appear at first brush.14 In the afore-cited manuscript, we concluded that the MDE nature is instead better summarised as follows (page 13, emphasis ours):
- MDE is an informal body of knowledge centred on the employment of modeling as the principal driver of software engineering activities.
- MDE promotes the pragmatic application of a family of related approaches to the development of software systems, with the intent of generating automatically a part or the totality of a software product, from one or more formal models and associated transformations.
- MDE is best understood as a vision rather than a concrete destination. A vision guides the general direction of the approach, but does not dictate the solution, nor does it outline the series of steps required to reach it.
- It is the responsibility of the MDE practitioner to select the appropriate tools and techniques from the MDE body of knowledge, in order to apply it adequately to a specific instance of the software development process. By doing so, the practitioner will create — implicitly or explicitly — an MDE variant.
The onus is thus on specific MDE variants, rather than on the body of knowledge itself, to lay down the details of how the model-driven approach is to be carried out. In this light, we have chosen to focus on two MDE variants, in order to better grasp the detail. The first is MDA, chosen not only due to its historical significance — in our opinion, it remains the most faithful embodiment of MDE's original spirit and vision — but also because it serves as an exemplary framework to demonstrate the application of MDE concepts. The second variant is AC-MDSD, which was selected because of its importance for MASD (cf. FIXME Chapter). As we shall see, these two variants are also of interest because they put forward contrasting approaches to MDE. Let us begin then by looking at the first of the pair.
Model Driven Architecture (MDA)
MDA is a comprehensive initiative from OMG and arguably the largest industry-wide effort to date, attempting to bring MDE practices to the wider software engineering community.15 Based on the OMG set of specifications — which include UML (- OMG 2017b) as a modeling language, the MOF (Meta-Object Facility) (- OMG 2016) as a metametamodel and QVT (Query / View/ Transformation) (- OMG 2017a) as a transformation language — MDA is designed to support all stages of software development lifecycle, from requirements gathering through to business modeling, as well as catering for implementation-level technologies such as CORBA (- OMG 2012).
Though more concrete and circumscribed than MDE, MDA is still considered an approach rather than a methodology, in and of itself.16 The approach's primary goals are "portability, interoperability, and reusability of software". (Group 2014). Beyond these, the MDA Manifesto (Booch et al. 2004) identifies a set of basic tenets that articulate its vision and which serve complementary purposes (Figure 1). These are as follows:
- Direct representation. There is a drive to shift the locus of software engineering away from technologists and the solution space, and place it instead in the hands of domain experts and on the problem space. The objective is to empower experts and to reduce the problem-implementation gap.17
- Automation. The aim is to mechanise all aspects of the development process that "do not depend on human ingenuity" (Booch et al. 2004). Automation is also crucial in addressing the problem-implementation gap because it is believed to greatly reduce interpretation errors.
- Open standards. By relying on open standards, MDA hoped to diminish or even eliminate Booch et al.'s "gratuitous diversity" (Booch et al. 2004) and to encourage the development of a tooling ecosystem designed around interoperability, with both general purpose tooling as well as specialised tools for niche purposes.18
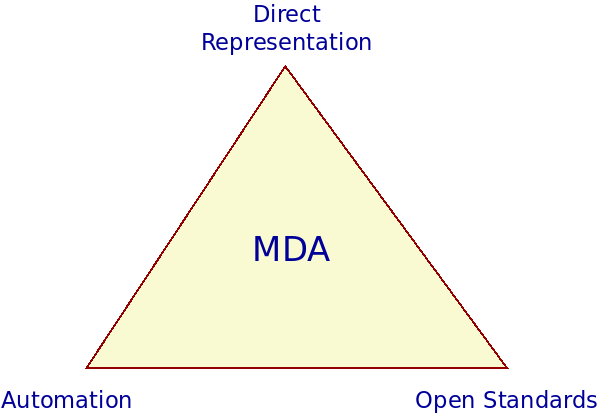
Figure 1: Basic tenets of the MDA. Source: Author's drawing based on an image from Booch et al. [cite:@booch2004mda.
Figure 2 presents a selection of MDA's basic terminology as per OMG documentation, which is, unsurprisingly, in line with the MDE terminology defined thus far — as well as that of the supplementary material (Craveiro 2021b). This is to be expected given the central role of MDA in the early development of MDE itself.19 A noteworthy term on that list is viewpoint, for MDA sees systems modeling as an activity with distinct vantage points or perspectives. Viewpoints give rise to architectural layers at different levels of abstraction, each associated with its own kind of models:
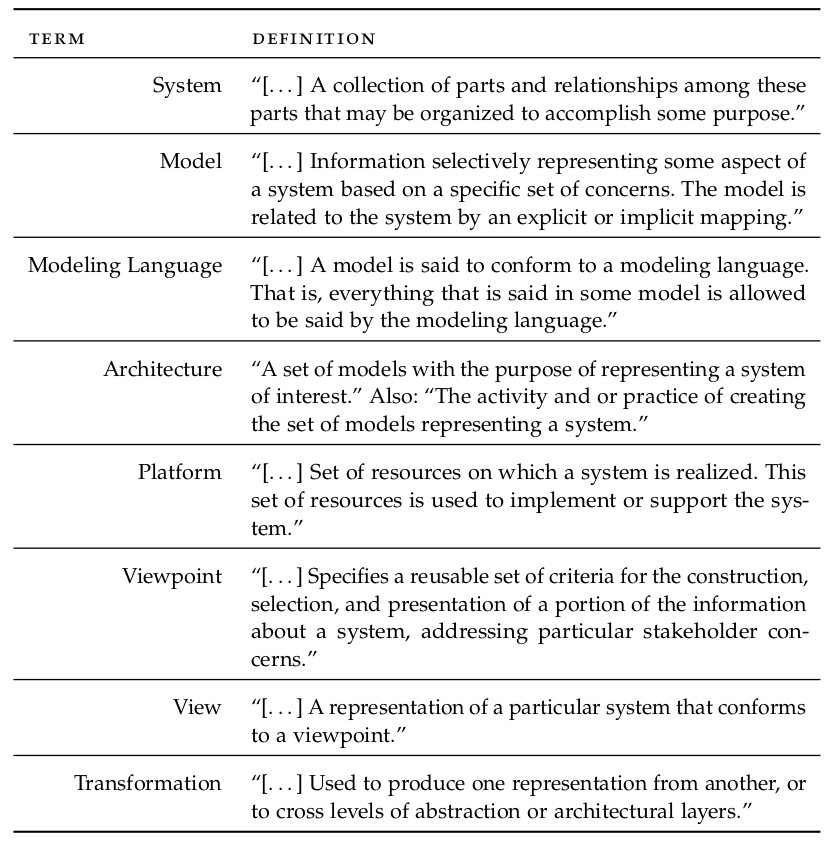
Figure 2: Key MDA terms. Source: MDA Guide [cite:@omg2014mda.
- Computation Independent Model (CIM): The "business or domain models" (Group 2014). Describes business functionality only, including system requirements. CIM are created by domain experts and serve as a bridge between these and software engineers.
- Platform Independent Model (PIM): The "logical system models" (Group 2014). PIMs describe the technical aspects of a system that are not tied to a particular platform.20
- Platform Specific Model (PSM): The "implementation models" (Group 2014). PSMs augment PIMs with details that are specific to a platform, and thus are very close to the implementation detail.
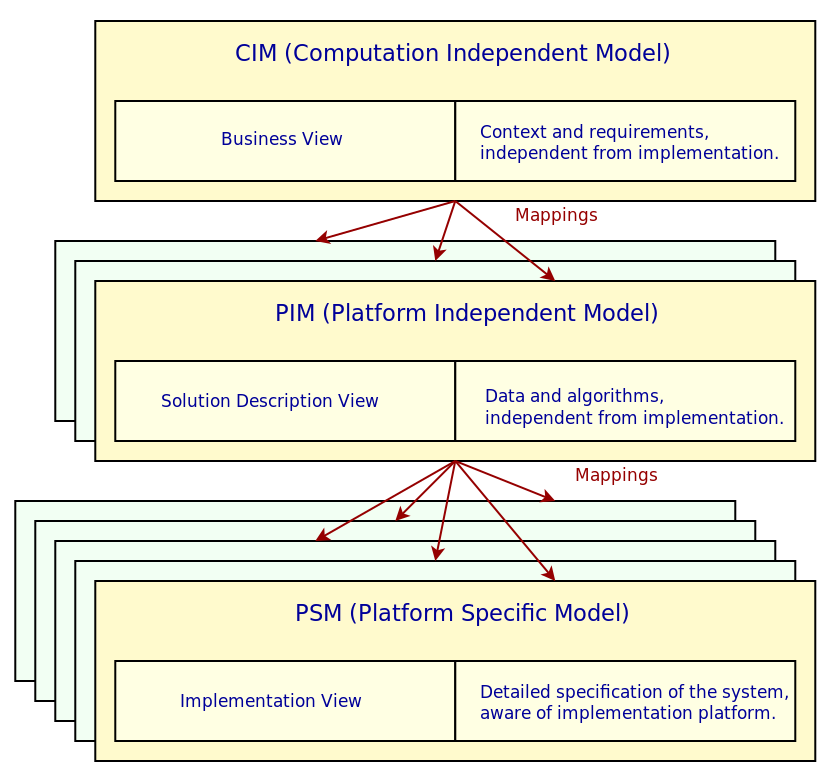
Figure 3: Modeling levels and mappings. Source: Author's drawing based on Brambilia et al.'s image (Brambilla, Cabot, and Wimmer 2012) (p. 45).
Figure 3 provides a simplified illustration of how the three types of models are related. Instance models are intended to be created using either UML — with appropriate extensions, as required, by means of UML Profiles — or via any other MOF based modeling language, preexisting or specifically created for the needs of the system. M2M transforms can be handled by QVT — including cascading transformations from CIM to PIM and to PSM — or by any other MOF based MT language such as ATL (Atlas Transformation Language) (Jouault et al. 2008). Finally, a large ecosystem of code generation tools, frameworks and standards have evolved for MDA, such as MOFScript (Oldevik et al. 2005), MOFM2T (- OMG 2008) and, arguably most significantly of all, the EMF (Eclipse Modeling Framework) (Steinberg et al. 2008) (Steinberg et al. 2009)21 — all of which which facilitate the generation of code from PSMs.
Faced with a potentially large number of heterogeneous models, a requirement often emerges to weave them together to form a consistent overall picture.22 Within MDA, this role is performed by model compilers. Whilst the literature does not readily supply a rigorous definition for the term, Mellor clearly delineates the role they are expected to play, as well as outlining their challenges (emphasis ours):
A model compiler takes a set of executable UML models23 and weaves them together according to a consistent set of rules. This task involves executing the mapping functions between the various source and target models to produce a single all-encompassing metamodel […] that the includes all the structure, behavior and logic — everything — in the system. […] Weaving the models together at once addresses the problem of architectural mismatch, a term coined by David Garlan to refer to components that do not fit together without the addition of tubes and tubes of glue code, the very problem MDA is intended to avoid! A model compiler imposes a single architectural structure on the system as a whole. (Mellor 2004)
Outside of executable models, model compilers are often associated with MDA code generation, transforming PIM and PSM directly into source code. The line between MDA's code generators and model compilers is blurry, both due to the imprecise terminology as well as the fact that code generators often need to conduct some form of model weaving prior to code generation. Several MDA code generators exist, including AndroMDA24 and Jamda25, and these typically allow for extensibility by means of plug-ins — the much maligned cartridges.26
And it is with cartridges that we round-off MDA's concepts relevant to MASD. Clearly, an overview as brief as the present cannot do justice to the breadth and depth of MDA. However, for all of its impressive achievements, MDA is not without its detractors. Part of the problem stems from the early overambitious claims, which, as we shall see in FIXME Chapter, were not entirely borne out by evidence.27 In addition, UML itself has been a source of several criticisms, including sprawling complexity, a lack of formality in describing its semantics, too low a level of abstraction, and the difficulties in synchronising the various UML models needed to create a system.28
Certain challenges are wider than UML and pertain instead to OMG's stance towards standardisation. On one hand, open and detailed specifications undoubtedly facilitated MDA's adoption and helped create a large and diverse tooling ecosystem. On the other hand, they also abetted an heterogeneous environment with serious interoperability challenges, populated by large and complex standards that forced practitioners to have a deep technical knowledge in order to make use of them. As a result, numerous aspects of these standards are not fully utilised by practitioners, with many either ignoring them altogether or resorting to more trivial use cases. There is also a real danger of ossification, with some standards not seeing updates in years — partially because the processes for their development are drawn-out and convoluted.
This state of affairs led Thomas to conclude that the best course of action is perhaps a lowering of expectations: "Used in moderation and where appropriate, UML and MDA code generators are useful tools, although not the panaceas that some would have us believe." (Thomas 2004) Reading between the lines, one is led to conclude that at least part of MDA's problems stem from its vast scope. It is therefore interesting to compare and contrast it with the next variant under study, given it takes what could be construed as a diametrically opposed approach.
Architecture-Centric MDSD (AC-MDSD)
Product of several years of field experience, Stahl et al. introduced AC-MDSD as a small part of their seminal work on MDSD (Völter et al. 2013) (p. 21).29 In their own words, "[…] AC-MDSD aims at increasing development efficiency, software quality, and reusability. This especially means relieving the software developer from tedious and error-prone routine work." Though it may be argued that the concepts around M2P (Model-to-Platform) transforms for infrastructural code were already well-established within MDE, having their roots in ideas such as MDA model compilers and MDA code generators (cf. Section MDA), it is important to note that AC-MDSD has very few commonalities with MDA. It is a minimalist approach, specified only at a high-level of abstraction and inspired mainly by practical experimentation.
AC-MDSD's very narrow focus makes it a suitable starting point for the exploration of model-driven approaches, as Stahl et al. go on to explain (emphasis ours):
We recommend you first approach MDSD via architecture-centric MDSD, since this requires the smallest investment, while the effort of its introduction can pay off in the course of even a six-month project. Architecture-centric MDSD does not presuppose a functional/professional domain-specific platform, and is basically limited to the generation of repetitive code that is typically needed for use in commercial and Open Source frameworks or infrastructures (sic.). (Völter et al. 2013) (p. 369)
The core idea behind AC-MDSD emanates from Stahl et al.'s classification of source code into three categories:
- Individual Code: Code crafted specifically for a given application, and which cannot be generalised.
- Generic Code: Reusable code designed to be consumed by more than one system.
- Schematic and Repetitive Code: Also known as boilerplate or infrastructure code, its main purpose is to perform a coupling between infrastructure and the application, and to facilitate the development of the domain-specific code.
As represented diagrammatically in Figure 4, schematic and repetitive code can amount to a significant percentage of the total number of LOC in a given system, with estimates ranging between 60% to 70% for web-based applications (Völter et al. 2013) (p. 369) and 90% or higher for embedded systems development (Czarnecki 1998).30,31 Besides the effort required in its creation, infrastructure code is also a likely source of defects because its repetitive nature forces developers to resort to error prone practices such as code cloning (Staron et al. 2015). Code generators do exist to alleviate some of the burden — such as wizards in IDE and the like — but they are typically disconnected and localised to a tool, with no possibility of having an overarching view of the system. Thus, the goal of AC-MDSD is to provide an holistic, integrated and automated solution to the generation of infrastructural code.
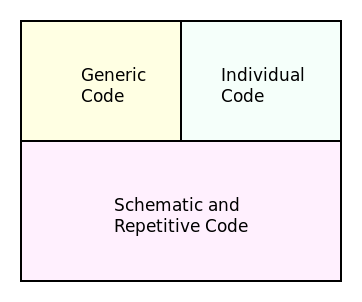
Figure 4: Categories of code in a system. Source: Author's drawing based on an image from Stahl et al. (Völter et al. 2013) (p. 15)
Following this line of reasoning, Stahl et al. theorise that systems whose software architecture has been clearly specified have an implementation with a strong component of schematic and repetitive programming; that is, the system's architecture manifests itself as patterns of infrastructural code, thus ultimately leading to the idea of generative software architectures. In a generative software architecture, the schemata of the architecture is abstracted as elements of a modeling language; domain models are created for an application, and, from these, code generators create the entire set of infrastructural code. In the simplest case, the modeling language can be created as a UML Profile with the required architectural concepts, and the instance models then become PIM (cf. Section MDA). For simplicity, Stahl et al. recommend bypassing explicit transformations into PSMs prior to code generation, and generate code directly from the PIM instead. Once a generative software architecture is put in place, only a small step is required to move towards the creation of product lines.
With regards to the construction of software systems, Stahl et al. propose a two-track iterative development model, where infrastructural engineering is expressly kept apart from application development, though allowing for periodic synchronisation points between the two — a useful take that is not without its dangers, as will be shown shortly. In addition, given only infrastructural code is targeted, AC-MDSD presupposes a need for integrating handcrafted code and generated code, with full code generation explicitly defined as a non-goal. The onus is on the MDE practitioner to determine the most suitable integration approach for the system in question, aided and abetted by the literature — for instance, by deploying the techniques such as those surveyed by Greifenberg et al. (Greifenberg et al. 2015a) (Greifenberg et al. 2015b).
Experience reports of AC-MDSD usage in various contexts do exist, though they are by no means numerous and appear to lack a critical analysis of theory and application (Al Saad et al. 2008) (Escott, Strooper, King, et al. 2011) (Escott, Strooper, Suß, et al. 2011) (Manset et al. 2006). The paucity may be attributable, at least in part, to researchers employing terminology other than AC-MDSD, rather than to the principles espoused — the afore-cited evidence, anecdotal though it may be, does suggest a favouring of the overall approach by software engineers when they embark on MDE.32 In the absence of authoritative points of view, we have chosen to undertake a critique from personal experience, rooted on our adoption of AC-MDSD on a large industrial project (Craveiro 2021a). Whilst limited, and though it pre-empts the discussion on MDE adoption (cf. FIXME Chapter), there are nevertheless advantages to this take, since the principal difficulty with AC-MDSD lies on the specifics of its application rather than with the sparseness of the theoretical framework.
We shall start by identifying the importance of AC-MDSD, which in our opinion is understated in the literature. As Stahl et al.'s quote above already hinted, infrastructural code is seen as low-hanging fruit for MDE because it is arguably the most obvious point to automate in the development of a software system. Carrying on from their analysis, our position is that the following interdependent factors contribute to this outcome:33
- Ubiquitous Nature: Infrastructural code is prevalent in modern software systems, as these are composed of a large number of building blocks34 which must be configured and orchestrated towards common architectural goals. It is therefore a significant problem, and its only increasing with the unrelentingly growth of software (cf. Section The Importance of Code Generation).
- Deceptively Easy to State: Unlike other applications of MDE, the issues addressed by AC-MDSD are easy to state in a manner comprehensible to all stakeholders. Existing systems have numerous exemplars that can serve as a basis for generalisation — employable simultaneously as a source of requirements, as well as a baseline for testing generated code. For new systems, engineers can manually craft a small reference implementation and use it as the target of the automation efforts, as did we, twice — (Craveiro 2021a) Section 4.5, and FIXME Section of the present document.
- Deceptively Easy to Measure: The costs associated with the manual creation and ongoing maintenance of infrastructural code are apparent both to software engineers as well as to the management structure, because they are trivially measurable — i.e. the total resource-hours spent creating or maintaining specific areas of the code base against the resource-hour cost is a suitable approximation. Engineers also know precisely which code they intend to replace, because they must identify the schematic and repetitive code. As a corollary, simplistic measures of cost savings are also straightforward to impute.35
- Deceptively Easy to Implement: The creation of technical solutions to realise AC-MDSD are deceptively simple to implement, as there is an abundance of template-based code generation tools that integrate seamlessly with existing programming environments — e.g. Microsoft's T4 (Vogel 2010) (p. 249), EMF's XText (Eysholdt and Behrens 2010), etc.36 These tools are supplied with a variety of examples and target software engineers with little to no knowledge of MDE.
- Produces Results Quickly: As already noted by Stahl et al., limited efforts can produce noticeable results, particularly in short to medium timescales but, importantly, the full consequence of its limitations play out at much longer timescales.
Perhaps because of these factors, many localised AC-MDSD solutions have been created which solve non-trivial problems, meaning the approach undoubtedly works. However, in our experience, AC-MDSD has inherent challenges which we ascribe to the following interrelated reasons.
Firstly, it exposes end-users to the complexities of the implementation and that of MDE theory, discouraging the unfamiliar. Paradoxically, it may also result in approaches that ignore MDE entirely — that which we termed unorthodox practitioners37 in (Craveiro 2021a) — and thus present inadequate solutions to problems that have already been addressed competently within the body of knowledge. This happens because its easy to get up-and-running with the user friendly tooling — that is, without any foundational knowledge — but soon the prototype becomes production code, and mistakes become set in stone; before long, a Rubicon is crossed beyond which there is just too much code depending on the generated code for radical changes to be feasible.
Secondly, the more automation is used, the higher the cost of each individual solution because customisation efforts require a non-negligible amount of specialised engineering work, and will need continual maintenance as the product matures. The latter is of particular worry because these costs are mostly hidden to stakeholders, who may have been led to believe that the investment in infrastructural code "had already been made", rather than seeing it as an ongoing concern throughout the life of a software system.
The third problem arises as the interest on the technical debt (Cunningham 1992) accrued by the first three factors comes due. Naive interpretations of AC-MDSD inadvertently trade velocity and simplicity in the short term for complexity and maintenance difficulties in the long term — at which point all deceptions are unmasked.38 This temporal displacement means that when the consequences are ultimately felt, they are notoriously difficult to quantify and address; by that time, the system may be on a very different phase of its lifecycle (i.e. maintenance phase).
Fourthly, end-users are less inclined to share solutions because the commonalities between individual approaches at the infrastructural level may not be immediately obvious due to a lack of generalisation. Knowledge transfer is impaired, we argue, because practitioners and tool designers view their infrastructural code as inextricably linked to the particular problem domain they are addressing or to a specific tool, and thus each developer becomes siloed on an island of their own making. This notion is reinforced by MDE's vision of every developer as a competent MDE practitioner, able to deploy the body of knowledge to fit precisely its own circumstances, and further compounded by MDE's focus on the problem space rather than the solution space.39 Conversely, aiming for generalisation is only possible once practitioners have mastered the MDE cannon, which takes time and experience. Thus, systems with similar needs may end up with their own costly solutions, having little to no reuse between them.
Alas, generalisation is no silver bullet either, as attested by the fifth and final challenge: that of problem domain decoupling.40 This issue emerges as the emphasis shifts from special purpose AC-MDSD solutions towards a general purpose approach, within a two-track development framework. With this shift, the relative scopes of the application domain versus the infrastructural domain also shift accordingly, and what begins as a quantitative change materialises itself as a qualitative change. Figure 5 models a simplified version of the dynamic in pictorial form, though perhaps implying a discreteness to the phenomena which is not necessarily present in practice.
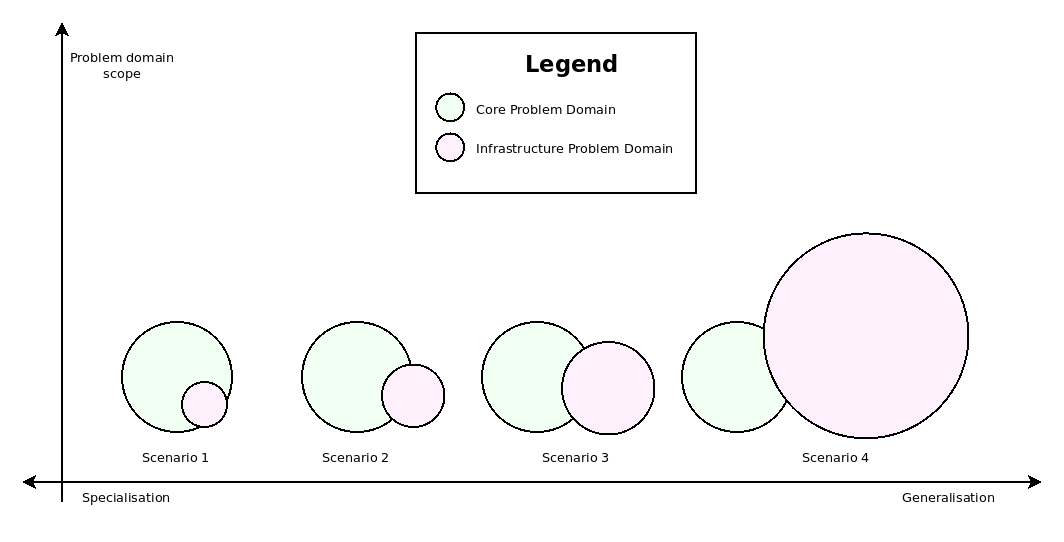
Figure 5: Problem domain decoupling. Source (Craveiro 2021b) (p. 46)
Though subtle at first, these changes are eventually felt for (emphasis theirs):
[…] as the scope of the infrastructural domain grows, it becomes a software product in its own right. Thus, there is an attempt to simultaneously engineer two tightly interlocked software products, each already a non-trivial entity to start off with. At this juncture one may consider the ideal solution to be the use of vendor products as a way to insulate the problem domains. Unfortunately, experimental evidence emphatically says otherwise, revealing that isolation may be necessary but only up to a point, beyond which it starts to become detrimental. We name this problem over-generalisation.41 (Craveiro 2021b) (p. 47)
In other words, there is a fine balancing act to be performed between under and over generalisation, with regards to the infrastructural domain and the problem domain; finding the right balance is a non-trivial but yet essential exercise (emphasis theirs):
What is called for is a highly cooperative relationship between infrastructure developers and end-users, in order to foster feature suitability — a relationship which is not directly aligned with traditional customer-supplier roles; but one which must also maintain a clear separation of roles and responsibilities — not the strong point of relationships between internal teams within a single organisation, striving towards a fixed goal. Any proposed approach must therefore aim to establish an adequate level of generalisation by mediating between these actors and their diverse and often conflicting agendas. We named this generalisation sweet-spot barely general enough, following on from Ambler’s footsteps (Ambler 2007)42, and created Figure 5.5 to place the dilemma in diagrammatic form. (Craveiro 2021b) (p. 47)
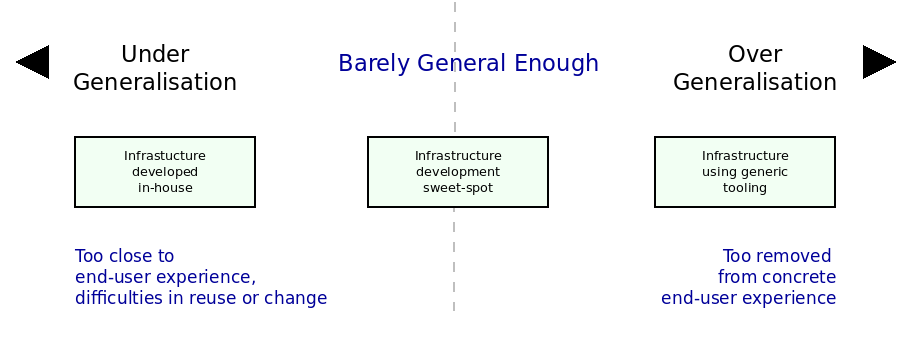
Figure 6: Different approaches to infrastructure development. Source (Craveiro 2021b) (p. 48)
As we shall see (cf. FIXME Chapter), this quest for an approach targeting the barely general enough sweet-spot has greatly influenced the present work.
In summary, our opinion is that those very same attributes that make AC-MDSD amenable as a starting point for MDE exploration are also closely associated with its most significant downsides. Interestingly, this double-edged sword characteristic is not unique to AC-MDSD, but instead generalises well to MDE — as the next chapter will describe in detail.
Bibliography
Footnotes:
Much can be said about metrics used to describe the size of a software product. Whilst aware of LOC's limitations — Jones went as far as calling it "one of the most imprecise metrics ever used in scientific or engineering writing" (Jones 1994) — we settled on this simplistic measure because the point under consideration is unaffected by its deficiencies.
That may change in the future as Machine Learning (ML) becomes more entrenched.
In (Beyer et al. 2016) (p. 67), Murphy makes a recent case for the value of automation by associating it with the following characteristics: a) Scale: automated systems can be designed to scale up and down very quickly, in response to external stimuli. b) Consistency: actions performed by machines yield results that are consistent over time. c) Platform creation: when designed adequately, the automated system becomes a platform upon which one can build and even leverage for other purposes. c) Faster repairs: Murphy alleges that the result of regular and successful automation is a reduced Mean Time To Repair (MTRR). d) Faster action: humans usually are unable to react as fast as machines, particularly in cases where the response is well-defined such as fail-over. e) Time saving: whilst difficult to calculate in practice, the most often cited benefit for automation is the freeing up of human resources to perform other tasks which cannot be so readily taken by machines.
Take its plain-text nature. Raymond dedicates an entire section in his opus (Raymond 2003) to "The Importance of Being Textual" (Section 5.1), where he makes an impassioned defense of textual representations over binary formats. His thesis could be summed up with the following passage: "Text streams are a valuable universal format because they're easy for human beings to read, write, and edit without specialized tools. These formats are (or can be designed to be) transparent." (Raymond 2003) (p. 107)
The battle for textual representations has been fought in many fronts; from our perspective, the use of graphical versus textual notations in modeling is of particular significance. Whilst results remain far from conclusive, the anecdotal evidence in the literature does seem to tilt in favour of textual notations, at least for some types of activities (Meliá et al. 2016) (Petre 1995).
Biermann defines it as follows (Biermann 1985) (emphasis his):
Computer programming is the process of translating a variety of vague and fragmentary pieces of information about a task into an efficient machine executable program for doingthat task. Automatic computer programming or automatic programming occurs whenever a machine aids in this process.
Fisher outlines a compelling vision of that promised future in Chapter 17, "Technological Trends in CASE" (Fisher and Fisher 1988) (p.281).
In its heyday, the CASE tooling market counted with hundreds of products. Fisher lists 35 tool vendors dedicated solely to design and analysis specification tools (Fisher and Fisher 1988) (Appendix A).
Fisher admits that "the mechanisms for automatically translating a requirement's specification […] still lack rigorous definitions. The inherent problem is the diversity and the imprecision of the present specification techniques." (Fisher and Fisher 1988) (p. 287).
Problem space and solution space are key concepts within MDE and MASD — the latter more so than the former. In (Craveiro 2021b), Chapter 4 is dedicated to their exposition.
Rompf et al.'s recent assessment of GP had an unmistakably dour tone (emphasis ours): "While the general idea of program generation is already well understood and many languages provide facilities to generate and execute code at runtime […], generative programming remains somewhat esoteric — a black art, accessible only to the most skilled and daring of programmers." (Rompf et al. 2015)
The choices are varied, be it in the form of detailed assessments such as Völter's (Völter et al. 2013), syntheses of the kind put forward by Brambilla (Brambilla, Cabot, and Wimmer 2012), or state of the art reviews in the vein of Oliveira's (OLIVEIRA 2011) and Jörges' (Jörges 2013).
This quote was translated from the original Spanish by the author. The reader is advised to consult the primary source.
A deeper questioning of the nature of MDE was performed by the author in (Craveiro 2021b) (Chapter 2). More generally, MASD makes use of a much wider subset of MDE's theoretical underpinnings than it feasible to discuss in detail within the present manuscript, so its exposition was relegated to supplemental material (Craveiro 2021b). Whilst these notes are extremely relevant to MASD, its absence on the primary material does not weaken the main argument of the dissertation — thus justifying their exclusion. If, however, you are seeking a more comprehensive background, the notes are recommended reading.
It is difficult to overstate MDA's significance in shaping MDE. Brambilla et al. believe it is "currently the most known modeling framework in industry" (Brambilla, Cabot, and Wimmer 2012) (p. 43); in Jörges assessment, it is "perhaps the most widely known MD* approach" (Jörges 2013) (p. 23); Asadi and Ramsin attribute MDE's familiarity amongst software engineers to "the profound influence of the Model Driven Architecture (MDA)." (Asadi and Ramsin 2008)
For an analytical survey of MDA based methodologies, see Asadi and Ramsin (Asadi and Ramsin 2008).
Problem space, solution space and problem-implementation gap are all described in detail on (Craveiro 2021b) (Chapter 4).
Booch et al.'s adverse reaction to "gratuitous diversity" is best understood in the context of CASE (cf. Section CASE).
According to Bézevin, "MDA may be defined as the realization of MDE principles around a set of OMG standards like MOF, XMI, OCL, UML, CWM, SPEM, etc." (Bézivin 2005)
The definition presented on Figure 2 gives a simplistic view of terms such as platform. To understand the difficulties surrounding this and other related terms, see Chapter 4 of (Craveiro 2021b).
The EMF is a modeling suite that is seen by some as a modern interpretation of the MDA ideals. Steinberg et al. called it "MDA on training wheels." (Steinberg et al. 2008) (p. 15)
For these and other challenges related to complex model topologies and model refinement, see (Craveiro 2021b), Chapter 4.
While executable models are beyond the scope of the present dissertation, its worthwhile depicting its ambition. Mellor is once more of assistance (emphasis ours): "Executable models are neither sketches nor blueprints; as their name suggests, models run. […] Executable UML is a profile of UML that defines an execution semantics for a carefully selected streamlined subset of UML." (Mellor 2004)
Völter's criticism of the term is scathing: "[…] Cartridges is a term that get (sic.) quite a bit of airplay, but it’s not clear to me what it really is. A cartridge is generally described as a 'generator module', but how do you combine them? How do you define the interfaces of such modules? How do you handle the situation where to cartridges have implicit dependencies through the code they generate?" (Völter 2009).
Slogans such as Bézivin's "Model once, Generate everywhere" (Bézivin 2003) are examples of this optimism, as was the language of the MDA Manifesto itself (emphasis ours):
We believe that MDA has the potential to greatly reduce development time and greatly increase the suitability of applications; it does so not by magic, but by providing mechanisms by which developers can capture their knowledge of the domain and the implementation technology more directly in a standardized form and by using this knowledge to produce automated tools that eliminate much of the low-level work of development. More importantly, MDA has the potential to simplify the more challenging task of integrating existing applications and data with new systems that are developed. (Booch et al. 2004)
For a brief but insightful overview of the lessons learned from UML, see France and Rumpe (France and Rumpe 2007), Sections 5.1 ("Learning from the UML Experience: Managing Language Complexity") and 5.2 ("Learning from the UML Experience: Extending Modeling Languages").
For the purposes of this dissertation. MDSD is understood to be a synonym of MDE. See (Craveiro 2021b), Section 2.4, for an explanation of the various names employed under the MDE umbrella (cf. The Model-Driven Jungle).
Stahl et al. may have discerned the general notion of schematic and repetitive code, but they left the gory details of their identification as an exercise for the modeler, noting only in passing that applications are composed of (emphasis ours) "[…] a schematic part that is not identical for all applications, but possess the same systematics (for example, based on the same design patters)." (Völter et al. 2013) (p. 16) Whilst most developers are likely in agreement with this sentiment, in truth it offers little additional clarity on how to identify those "same systematics".
Our own personal experiences (Craveiro 2021a) corroborated these findings, both in terms of the existence of schematic and repetitive code as well as its relative size on a large industrial product.
A trait we ourselves share, including the lack of awareness of the existence of AC-MDSD, as narrated in (Craveiro 2021a).
This analysis is largely a byproduct of the analysis work done in Sections 7 and 8 of (Craveiro 2021a), as well as Chapter 5 of (Craveiro 2021b).
Building blocks are to be understood in the sense meant by Völter (Völter et al. 2013) (p. 59). See also Section 4.2.2 of (Craveiro 2021b) (p. 33).
The adjective simplistic is used here because we are performing a trivial extrapolation. It would be non-trivial to account for qualitative factors present in manual code, such as efficiency, robustness and many other non-quantitative properties in the domain of software quality, such as those identified by Meyer (Meyer 1988) (Chapter 1). These simplistic measurements can only indicate that generated code is no worse functionally than its manual counterpart.
Here we include tools such as AndroMDA and Jamda (cf. Section MDA) because, whilst typically associated with MDA, they can be deployed to fulfil an AC-MDSD role. In addition, for a more general treatment of these approaches, see (Craveiro 2021b), Chapter 3 (Section 3.7).
An unorthodox practitioner is one who engages in independent rediscovery of fundamental aspects of the MDE body of knowledge without the awareness of its existence.
For a reflection of our own experiences on the matter, see Section 6 of (Craveiro 2021a).
It is perhaps for these reasons that MDA code generators put forward concepts such cartridges: so that their end-users can extend a core to match their particular requirements. These are, in effect, elaborate code generation frameworks to satisfy the needs of developers. Interestingly, Jörges concluded that "[…] there is a high demand for approaches that enable a simple and fast development of code generators." In our opinion, developers do not want to create code generators, but find themselves having to do so. As we'll see in FIXME Chapter, demand is largely a function of inadequate tooling.
Problem domain decoupling is addressed in pages 46 to 49 of (Craveiro 2021b) (Chapter 5).
FIXME Chapter deal with the complex issues surrounding MDE adoption, including vendor tooling (FIXME Section in particular).
Ambler states that (emphasis ours) "[…] if an artifact is just barely good enough then by definition it is at the most effective point that it could possibly be at." (Ambler 2007)